Projeto de Clustering¶

Objetivo¶
Criar um sistema de recomendação utilizando o algoritmo não-supervisionado KMeans do Scikit-learn.
Neste projeto será utilizado uma base de dados com músicas do serviço de streaming de áudio Spotify.
Spotify¶
É um serviço de streaming de áudio, disponível em praticamente todas as plataformas e está presente no mundo todo. Foi lançado oficialmente em 2008, na Suécia. Possui acordos com a Universal Music, Sony BGM, EMI Music e Warner Music Group.
O usuário pode encontrar playlists e rádios, checar quais músicas estão fazendo sucesso entre os assinantes, criar coleções ou seguir as coleções de amigos e artistas. A plataforma conta com mais de 170 milhões de usuários e veio para o Brasil em 2014.
Importando as bibliotecas¶
# para identificar os arquivos em uma pasta
import glob
# para manipulação dos dados
import pandas as pd
import numpy as np
# para visualizações
import seaborn as sns
import matplotlib.pyplot as plt
# para pré-processamento
from sklearn.preprocessing import MinMaxScaler
# para machine learning do agrupamento
from sklearn.cluster import KMeans
# para ignorar eventuais warnings
import warnings
warnings.filterwarnings("ignore")
# algumas configurações do notebook
%matplotlib inline
pd.options.display.max_columns = None
plt.style.use('ggplot')
importando a base de dados¶
Vamos importar nossa base de dados, utilizando o método glob do framework de mesmo nome para buscar os arquivos ".csv" que contem na pasta, no nosso caso temos 2 arquivos referentes aos anos de 2018 e 2019. Em seguida utilizaremos um list comprehension para fazer a leitura dos dados com o método do pandas, com isso podemos já inserir dentro de uma lista vazia criada, concatenando esses dois elementos da lista, pelas linhas, formando um arquivo único e por fim, visualizamos o resultado com as primeiras 5 linhas com o método head().
Temos 20 colunas ou features em nosso conjunto, vamos conhecer cada uma delas com o nosso Dicionário de dados:
- name: nome da faixa
- album: album que contém a faixa
- artist: nome do artista
- release_date: ano de lançamento da faixa
- length: tempo de duração da música
- popularity: quanto mais alto o valor, maior a popularidade
- track_id: ID
- mode: Modo indica a modalidade (maior ou menor) de uma faixa, o tipo de escala da qual seu conteúdo melódico é derivado
- acousticness: quanto mais alto o valor, mais acústico é a música
- danceability: quanto mais alto o valor, mais dançante é a música com base nos elementos musicais
- energy: A energia da música, quanto mais alto o valor, mais enérgica é
- instrumentalness: o valor de nível instrumental, se mais cantada ou sem vocal
- liveness: presença de audiência, é a probabilidade da música ter tido público ou não
- valence: quanto maior o valor, mais positiva (feliz, alegre, eufórico) a música é
- loudness: quanto maior o valor, mais alto é a música
- speechiness: quanto mais alto o valor, mais palavras cantadas a música possui
- tempo: o tempo estimado em BPM (batida por minuto), relaciona com o ritmo derivando a duração média do tempo
- duration_ms: a duração da faixa em milisegundos
- time_signature: Uma estimativa de fórmula de compasso geral de uma faixa
- genre: Genero do artista
# identificando os arquivos .csv contidos na pasta
all_files = glob.glob("dados/*.csv")
# criando uma lista vazia para receber os dois arquivos
df_list = []
# fazendo um loop e armazenando os arquivos na pasta df_list
[df_list.append(pd.read_csv(filename, parse_dates = ['release_date'])) for filename in all_files]
# concatenando os dois arquivos para formar um
df = pd.concat(df_list, axis=0, ignore_index=True).drop('Unnamed: 0', axis=1)
# visualizando as primeiras 5 linhas
df.head()
Como extraimos também os IDs das músicas, que é a parte final da url, única para cada música, vamos juntar e formar a url completa.
# definindo a url padrão
url_standard = 'https://open.spotify.com/track/'
# unindo com os IDs de cada música
df['url'] = url_standard + df['track_id']
# removendo a coluna dos IDs
df.drop(['track_id'], axis=1, inplace=True)
# visualizando as primeiras duas linhas
df.head(2)
Assim como as primeiras 5 linhas, vamos também visualizar as 5 últimas, com o método tail()
# visualizando as últimas 5 linhas
df.tail()
Quais são as dimensões desse conjunto? O método shape pode nos ajudar a descobrir.
print(f"Quantidade de linhas: {df.shape[0]}")
print(f"Quantidade de colunas: {df.shape[1]}")
Análise Exploratória dos dados¶
Dados faltantes ou nulos, é uma característica normal para um conjunto de dados extraido no mundo real. Vamos dar uma olhada se esse conjunto possui algum.
# checando dados nulos
df.isnull().sum()
Puxando os dados diretamente desta API, notamos que não foram trazidos nenhum dado faltante.
Podemos notar que a maioria são dados numéricos, mas será que realmente estão nesse formato, vamos fazer um check utilizando o método *dtypes.
# checando os tipos de dados
df.dtypes
Podemos ver que os formatos estão de acordo com o que deveriam ser.
Vamos agora checar se há dados, ou melhor, linhas iguais ou duplicadas com o método duplicated(), caso encontramos vamos remover com o método drop_duplicates e checar as novas dimensões.
# checando dados duplicados
df.duplicated().sum()
# removendo linhas duplicadas
df.drop_duplicates(inplace=True)
df = df.reset_index()
# checando as novas dimensões
df.shape
# garantindo que não há mais dados duplicados
df.duplicated().sum()
Vamos dar uma olhada em algumas estatísticas, para conhecermos mais nossos dados, e pra isso fazemos uso do método describe().
# analisando estatísticas descritivas (numéricas)
df.describe()
Como argumentos padrões do próprio método, foram retornadas somente das variáveis numéricas, mas também podemos fazer isso para as variáveis categóricas passando o tipo como argumento.
# analisando estatísticas descritivas (categóricas)
df.describe(include='O')
Olhando somente para os números não são muito intuitivos, vamos então analisar graficamente, utilizado a biblioteca seaborn.
Primeiro, vamos criar um dataframe filtrando somente as variáveis de tipo numéricas, depois criaremos um loop para plotar os dados.
# separando o conjunto de dados em tipos numéricos
df_num = df.select_dtypes(['float64', 'int64'])
# definindo a área de plotagem
plt.figure(figsize=(14,8))
# plotando os gráficos
for i in range(1, len(df_num.columns)):
ax = plt.subplot(3, 5, i)
sns.distplot(df_num[df_num.columns[i]])
ax.set_title(f'{df_num.columns[i]}')
ax.set_xlabel('')
# otimizando o espaçamento entre os gráficos
plt.tight_layout()

Podemos notar vários tipos de distribuição entre as variáveis e escalas diferentes. A princípio fizemos isso mais para saber como são as distribuições, não vamos analisar nada muito a fundo nesse momento.
Vamos analisar também a correção entre essas variáveis, utilizando um heatmap.
# definindo a área de plotagem
plt.figure(figsize=(14,8))
# plotando o gráfico
sns.heatmap(df_num.iloc[:, 1:].corr(), vmin=-1, vmax=1, annot=True).set_title('Correlação entre as variáveis');

Analisando as correlações, podemos notar que algumas variáveis se correlacionam fortemente, então não há problema em remover pelo menos uma delas, dependendo o caso o modelo pode ficar enviesado, vou optar em remover pelo menos uma, de cada duas correlactionadas fortemente.
df_num.drop(['length', 'loudness'], axis=1, inplace=True)
Pré-processamento dos dados¶
Para o pré-processamento dos dados, vamos utilizar o MinMaxScaler do scikit-learn. Vamos normalizar porque como vimos acima, nas distribuições dos dados, as escalas são muito diferentes o framework é sensível à isso, se não fizermos isso poderá dar um resultado bem diferente do esperado.
O formato das distribuições continuarão as mesmas, porém estarão na mesma escala.
# instanciando o tranformador
scaler = MinMaxScaler()
# treinando e transformando os dados
scaled = scaler.fit_transform(df_num)
# colocando os dados transformados em um dataframe
df_scaled = pd.DataFrame(scaled, columns=df_num.columns)
# olhando o resultado
df_scaled.head()
Vamos confirmar o que foi dito, sobre as distribuições e escalas.
# definindo a área de plotagem
plt.figure(figsize=(14,8))
# plotando os gráficos
for i in range(1, len(df_scaled.columns)):
ax = plt.subplot(3, 5, i)
sns.distplot(df_scaled[df_scaled.columns[i]])
ax.set_title(f'{df_scaled.columns[i]}')
ax.set_xlabel('')
# otimizando o espaçamento entre os gráficos
plt.tight_layout()

Todas as escalas estão de 0 à 1.
Machine Learning¶
Agora vamos partir para o aprendizado do modelo, antes um breve introdução do algoritmo que será usado e como é seu funcionamento.
Clustering¶
Clustering é o conjunto de técnicas para análise de agrupamento de dados, que visa fazer agrupamentos automáticos de dados segundo o grau de semelhança. O algoritmo que vamos utilizar é o K-Means.
K-Means¶
Como funciona o algoritmo K-Means?
O K-Means agrupa os dados tentando separar as amostras em grupos de variancias iguais, minimizando um criterio conhecido como inertia ou wcss (within-cluster sum-of-squares), em português, soma dos quadrados dentro do cluster, ou seja, minimizar essa soma dentro do cluster, quanto menor, melhor o agrupamento.
Como definir a quantidade de grupos?
Uma técnica à se usar é a do cotovelo, com base na inertia ou wcss, onde definimos, basicamente, quando a diferença da inertia parar de ser significativa. Esse método compara a distância média de cada ponto até o centro do cluster para diferentes números de cluster.
Além do método do cotovelo, para identificar o melhor número de clusters para nossos dados, podemos também utilizar inspeção visual, conhecimento prévio dos dados e do negócio e as vezes já temos até um número pré-definido, dependendo do objetivo.
Exemplo de como funciona a técnica do cotovelo.
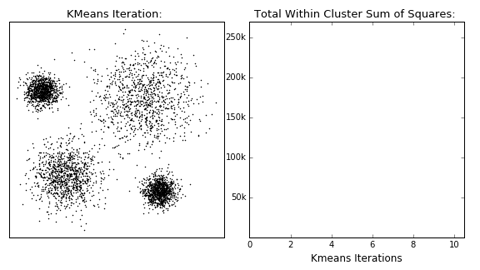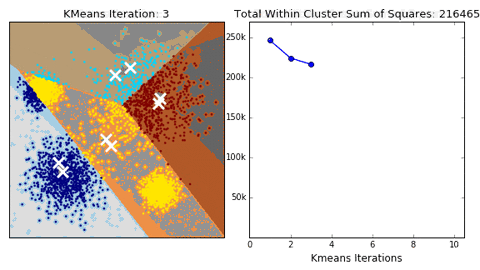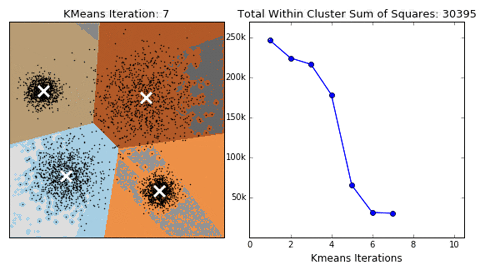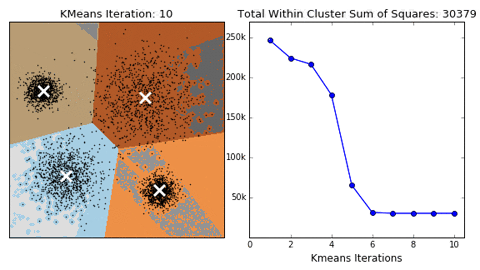
Vamos começar!
# criando uma lista vazia para inertia
wcss_sc = []
# criando o loop
for i in range(1, 50):
# instanciando o modelo
kmeans = KMeans(n_clusters=i, random_state=42)
# treinando o modelo
kmeans.fit(df_scaled.iloc[:, 1:])
# salvando os resultados
wcss_sc.append(kmeans.inertia_)
# plotando o Elbow Method
plt.figure(figsize=(12,6))
plt.plot(range(1, 50), wcss_sc, 'o')
plt.plot(range(1, 50) , wcss_sc , '-' , alpha = 0.5)
plt.title('Elbow Method')
plt.xlabel('Number of Clusters')
plt.ylabel('WCSS')
# plt.savefig('Elbow_Method.png')
plt.show()

Vamos fazer um teste com 20 grupos, pois podemos notar que a diferença não será mais muito significativa a partir desse valor. Claros que podemos testar com outros quantidades depois.
Então, vamos instanciar o modelo que vamos usar, definindo o número correto de clusters, e vamos ver como os dados foram separados.
# instanciando o modelo
kmeans = KMeans(n_clusters=20, random_state=42)
# treinando, excluindo a primeira linha que é o index
kmeans.fit(df_scaled.iloc[:, 1:])
# fazendo previsões
y_pred = kmeans.predict(df_scaled.iloc[:, 1:])
# Visualizando os clusters em um dataframe
cluster_df = pd.DataFrame(y_pred, columns=['cluster'])
# visualizando a dimensão
cluster_df.shape
Vamos unir o dataframe original com os grupos que o algoritmo definiu para cada linha.
# concatenando com o dataset original
df_new = pd.concat([df, cluster_df], axis=1)
# checando o dataframe
df_new.head()
# olhando a nova dimensão
df_new.shape
Analisando os clusters¶
Vamos responder algumas perguntas, relacionadas ao resultado.
Qual a média, desvio padrão, min e max dos elementos que compõe os clusters?¶
# agrupando por cluster e calculando a média
df_new.groupby('cluster')['name'].count().describe()
print(f"Temos em média {df_new.groupby('cluster')['name'].count().describe()['mean']:.2f} elementos por cluster, \
com um desvio padrão de {df_new.groupby('cluster')['name'].count().describe()['std']:.2f}.")
print(f"O Cluster com a menor quantidade de elementos possui {df_new.groupby('cluster')['name'].count().describe()['min']:.0f}\
e o maior possui {df_new.groupby('cluster')['name'].count().describe()['max']:.0f} elementos.")
Podemos notar uma certa dispersão nos dados, isso pode ser devido à coleta de dados não balanceadas.
sns.distplot(df_new.groupby('cluster')['name'].count())

Podemos notar que os grupos estão desbalanceados, precisaríamos levar em consideração as regras de negócios, para sabermos se os grupos criados estão adequados com base nas músicas, ritmos entre outros.
Vamos dar uma olhada nos números de outros atributos.
A popularidade entre os grupos seguem uma distribuição normal.¶
# agrupando por cluster e calculando a média
sns.distplot(df_new.groupby(['cluster'])['popularity'].mean())

df_new.groupby(['cluster'])['popularity'].mean().skew()
df_new.groupby(['cluster'])['popularity'].mean().kurtosis()
Com os resultados de skewness e kurtosis, vemos que os dados não obedecem a uma distribuição normal, isso pode ser caracterizado por amostras de diferentes populações.
Qual é o grupo com mais e menos elementos?¶
# checando o cluster com mais músicas
pd.DataFrame(df_new.cluster.value_counts()).reset_index()[:1].rename(columns={'index': 'cluster', 'cluster': 'qtd'})
# checando o cluster com menos músicas
pd.DataFrame(df_new.cluster.value_counts()).reset_index()[-1:].rename(columns={'index': 'cluster', 'cluster': 'qtd'})
Vamos dar uma olhada nos dados dos grupos que contém o menor conjunto de elementos.
df_new[df_new.cluster == 12]
Agora vamos salvar o dataframe com os respectivos grupos e para podemos analisar ou criar outras visualizações, com outros aplicativos como o Power BI ou Tableau, por exemplo.
Além do dataframe, vamos salvar o nosso modelo com treinado para utilizarmos em outra aplicação.
# # biblioteca que salvam os modelos
# import pickle
# # nome do modelo
# filename = 'model.pkl'
# # persistindo em disco local
# pickle.dump(kmeans, open(filename, 'wb'))
# # fazendo o download do modelo
# model_load = pickle.load(open("model.pkl", "rb"))
# # realizando as predições com o modelo treinado do disco
# model_load.predict(df_scaled.iloc[:, 1:])
# Create a Pandas Excel writer using XlsxWriter as the engine.
writer = pd.ExcelWriter('grupo_musicas.xlsx', engine='xlsxwriter')
# Convert the dataframe to an XlsxWriter Excel object.
df_new.to_excel(writer, sheet_name='Sheet1', index=False)
# Close the Pandas Excel writer and output the Excel file.
writer.save()
Conclusão¶
Criamos um framework para coleta dos dados direto da API do spotify e salvamos os dados em um arquivo .csv, fizemos algumas análises e pré-processamento dos dados.
Após criarmos um modelo de clusterização, o modelo fez as previsões para os grupos relacionados, colocamos todos em um dataframe e salvamos em um arquivo em excel.
Para os próximos passos, vamos criar uma POC (Proof of Concept) com o framework streamlit e publicar um dashboard criado com os dados em Power BI.
link para dashboard do Power BI: https://bit.ly/3j2KCiU
Há outros tipos de modelos para clusterização, mas utilizamos o KMeans por ser um dos mais utilizados e conseguir ter um bom resultado de forma fácil.
Referencias¶
https://developer.spotify.com/dashboard/applications/85bde5058f48488eb76c9a41fd7942eb
https://developer.spotify.com/documentation/web-api/reference/tracks/get-audio-features/
https://github.com/plamere/spotipy/tree/master/examples
https://morioh.com/p/31b8a607b2b0
https://medium.com/@maxtingle/getting-started-with-spotifys-api-spotipy-197c3dc6353b