Projeto - Segmentação de Clientes de Food Delivery¶
O Que é Segmentação de Clientes?¶
A segmentação de clientes é o processo de dividir os clientes em grupos com base em características comuns, para que as empresas possam comercializar para cada grupo de forma eficaz e adequada, ou simplesmente compreender o padrão de consumo dos clientes.

Por Que Segmentar Clientes?¶
A segmentação permite que os profissionais de marketing adaptem melhor seus esforços de marketing a vários subconjuntos de público-alvo. Esses esforços podem estar relacionados às comunicações e ao desenvolvimento de produtos. Especificamente, a segmentação ajuda uma empresa a:
Criar e comunicar mensagens de marketing direcionadas que ressoarão com grupos específicos de clientes, mas não com outros (que receberão mensagens personalizadas para suas necessidades e interesses).
Selecionar o melhor canal de comunicação para o segmento, que pode ser e-mail, publicações em mídias sociais, publicidade em rádio ou outra abordagem, dependendo do segmento.
Identificar maneiras de melhorar produtos ou novas oportunidades de produtos ou serviços.
Estabelecer melhores relacionamentos com os clientes.
Testar as opções de preços.
Concentrar-se nos clientes mais rentáveis.
Melhorar o atendimento ao cliente.
Escolher entre venda por atacado e venda cruzada de outros produtos e serviços.
Como Segmentar Clientes?¶
A segmentação de clientes exige que uma empresa colete informações específicas - dados - sobre clientes e analise-as para identificar padrões que podem ser usados para criar segmentos.
Parte disso pode ser obtida a partir de informações de compra - cargo, geografia, produtos adquiridos, por exemplo. Algumas delas podem ser obtidas da forma como o cliente entrou no seu sistema. Um profissional de marketing que trabalha com uma lista de e-mail de inscrição pode segmentar mensagens de marketing de acordo com a oferta de inscrição que atraiu o cliente, por exemplo. Outras informações, no entanto, incluindo dados demográficos do consumidor, como idade e estado civil, precisarão ser adquiridas de outras maneiras.
Os métodos típicos de coleta de informações incluem:
- Entrevistas presenciais ou por telefone
- Pesquisas
- Coleta de informações publicadas sobre categorias de mercado
- Grupos de foco
- Dados de acessos a sistemas ou apps
Usando Segmentos de Clientes¶
Características comuns nos segmentos de clientes podem orientar como uma empresa comercializa segmentos individuais e quais produtos ou serviços ela promove. Uma pequena empresa que vende guitarras feitas à mão, por exemplo, pode decidir promover produtos com preços mais baixos para guitarristas mais jovens e guitarras premium com preços mais altos para músicos mais velhos, com base no conhecimento do segmento que lhes diz que os músicos mais jovens têm menos renda disponível do que seus colegas mais velhos.
A segmentação de clientes pode ser praticada por todas as empresas, independentemente do tamanho ou setor, e se vendem on-line ou presencialmente. Começa com a coleta e a análise de dados e termina com a atuação nas informações coletadas de maneira apropriada e eficaz, com a entrega das conclusões.
Carregando os Pacotes¶
# Manipulação e visualização de dados
import time
import sklearn
import datetime
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib as m
import matplotlib.pyplot as plt
# Machine Learning
from sklearn.cluster import KMeans
from sklearn import metrics
from sklearn.preprocessing import MinMaxScaler
from sklearn.decomposition import PCA
# Pacotes para o gráfico 3D
import plotly as py
import plotly.express as px
import plotly.graph_objs as go
py.offline.init_notebook_mode(connected = True)
# Formatação dos gráficos
plt.style.use('fivethirtyeight')
plt.figure(1 , figsize = (15 , 6))
%matplotlib inline
Carregando e Compreendendo os Dados¶
# Carrega o dataset
df_food_delivery = pd.read_csv("dados/data.csv", encoding = 'utf-8', sep=';')
# Shape
df_food_delivery.shape
# Visualiza os dados originais
df_food_delivery.head()
Dicionário de Dados¶
Abaixo você encontra o dicionário de dados do dataset usado no projeto.
- id_transacao: ID da transação. Um mesmo ID pode ter vários itens de um pedido.
- horario_pedido: Horário exato do pedido.
- localidade: Localidade que processou o pedido (unidade do restaurante).
- nome_item: Nome do item (pizza, salada, bebida e sobremesa).
- quantidade_item: Quantidade de itens no pedido.
- latitude: Latitude da localidade onde o pedido foi gerado.
- longitude: Longitude da localidade onde o pedido foi gerado.
Análise Exploratória¶
A análise exploratória de dados emprega grande variedade de técnicas gráficas e quantitativas, visando maximizar a obtenção de informações ocultas na sua estrutura, descobrir variáveis importantes em suas tendências, detectar comportamentos anômalos do fenômeno, testar se são válidas as hipóteses assumidas, escolher modelos e determinar o número ótimo de variáveis.
Vamos explorar os dados por diferentes perspectivas e compreender um pouco mais o relacionamento entre as variáveis. Começamos em analisar a quantidade de dados únicos presentes em cada coluna.
# Verifica o total de valores únicos por coluna
df_food_delivery.nunique()
Podemos observar que temos 100.000 transações neste conjunto de dados, porém, podemos notar que as outras são menos em quantidades de entradas, isso pode significar que os pedidos não são únicos, sempre são acompanhados em mais de um produto.
Agora, será que o interpretador importou os dados corretamente, vimos que aparentemente temos dados strings e numéricos, mas nem sempre ele importa corretamente, por isso vamos analisar com o método dtypes.
# Tipos de dados
df_food_delivery.dtypes
O formato estão corretos, então não vamos precisar fazer nenhum tipo de conversão.
Outra forma de ter uma idéia sobre conteúdo do dataset é utilizando o método describe() para visualizar as principais estatísticas dos dados, e podemos visualizar tanto dos dados numéricos quanto categóricos, pra este último basta passar o parâmetro include="O".
# Resumo das colunas numéricas
df_food_delivery.describe()
# Resumo das colunas categóricas
df_food_delivery.describe(include='O')
Vemos que a média de pedidos é a aproximadamente 2, provavelmente um pessoa que pede pizza, também pede no mínimo um suco para acompanhar, por exemplo, mas temos pedidos com 1 item, assim como o máximo de pedidos é 5.
Agora vamos criar uma tabela que nos fornecerá o número de vezes que cada item foi solicitado em cada pedido, vamos fazer isso criando uma tabela pivot, esta tabela basicamente transformará, no nosso caso, os valores únicos da coluna pedido em colunas individuais, e manteremos as colunas id_transacao, horario_pedido e localidade também.
Na sequencia daremos uma olhada no formato dessa tabela e visualizar as 10 primeiras entradas.
# criando a tabela pivot
df_item_pedidos = df_food_delivery.pivot_table(index = ['id_transacao', 'horario_pedido', 'localidade'],
columns = ['nome_item'],
values = 'quantidade_item').rename_axis(None, axis=1)
# verificando as primeiras linhas
df_item_pedidos.head(10)
Podemos notar que algumas células estão como NaN, isso significa que não houve pedido então podemos considerar esses valores como 0 e preencher isso com o método fillna() e vamos aproveitar usar o reset_index() e manter todas as colunas no mesmo nível.
Podemos notar também que os números estão como tipo float(), embora não influenciar nos resultados, vamos alterar para o tipo int com o método astype().
Em seguida vamos dar uma olhada nas dimensões dessa nova tabela, assim como verificar os valores não unicos também na sequencia.
# preenchendo com 0 e resetando index
df_item_pedidos = df_item_pedidos.fillna(0).reset_index()
# convertendo de float para int
df_item_pedidos[['bebida', 'pizza', 'salada', 'sobremesa']] = df_item_pedidos[['bebida', 'pizza', 'salada', 'sobremesa']].astype(int)
# Shape
df_item_pedidos.shape
# Verifica o total de valores únicos por coluna
df_item_pedidos.nunique()
Então vamos ver como ficaram essas mudanças, visualizando as primeiras 5 primeiras linhas de entrada.
# Visualiza o resultado do pivot
df_item_pedidos.head()
Novamente olharemos as estatísticas nesse novo formato de tabela com em relação aos pedidos e conferir se não temos mais dados nulos.
# Describe
df_item_pedidos.describe()
# Não podemos ter valores nulos
df_item_pedidos.isnull().sum()
Agora podemos ver que, em média, pizza e sobremesa são os itens que mais são pedidos e salada é o item que menos pedem. E realmente não possuimos mais dados nulos nesse dataframe.
Ajuste de Índices¶
Para segmentar os pedidos dos clientes, precisamos de uma coluna de identificação de cada registro. Não podemos usar id_transacao, pois essa coluna representa um dado válido e além disso não é um valor único, logo não pode ser usado como índice.
Vamos então criar uma coluna usando o índice atual e checar pra ver como ficou.
# Índice
df_item_pedidos.index
# Fazemos o reset no índice e gravamos o resultado em outro dataframe
df_item_pedidos_idx = df_item_pedidos.reset_index()
# Pronto, agora temos uma coluna de ID com valor único para cada registro
df_item_pedidos_idx.head()
# Dataset
df_item_pedidos
Análise Descritiva¶
A Análise Descritiva fornece conhecimento, oferecendo compreensão dos acontecimentos, com base nos fatos, registros dos dados. É uma etapa simples do Business Analytics e também a fase inicial do estudo e das análises das informações.
Distplot dos Atributos Usados Para Segmentação¶
Vamos começar analisando os histogramas das nossas variáveis numéricas, para cada item do pedido e a localidade, e vamos criar com a função Distplot do seaborn.
# configurando a área de plotagem
plt.figure(figsize=(15, 6))
# inicializa o contador
n = 0
# define a lista para visualização
items_loc_list = ['pizza', 'salada', 'sobremesa', 'bebida', 'localidade']
# loop pelas colunas
for i in items_loc_list:
n += 1
plt.subplot(1 , 5 , n)
plt.subplots_adjust(hspace = 0.5 , wspace = 0.5)
sns.distplot(df_item_pedidos[i] , bins = 20)
plt.title(f'Distribuição de {i}')
plt.show()

Analisando os gráficos, podemos ver que 1 pizza é o pedido mais comum e 3 e 5 são os menos pedidos, pouquissimas pessoas pedem salada, visto que a grande maioria salada não é pedido, todos os pedidos contém, pelo menos 1 sobremesa, mas nem todos pedem bebida, que por sinal é em sua maioria e por fim notamos que as localidade 2 e 6 fazem mais pedidos que as demais.
Com base nessa distribuição, é possivel conhecer alguns padrões mas ainda não conseguimos relacionar, somente levantar algumas hipóteses que poderão ser verificadas mais a frente.
Gráfico de Total de Pedidos Por Localidade¶
Fazendo um gráfico por localidade, podemos comprovar o que a distibuição nos mostrou a maioria nas localidades 2 e 6, assim podemos fazer com os outros gráficos, caso desejar.
# Plot
plt.figure(figsize = (15 , 5))
sns.countplot(x = 'localidade' , data = df_item_pedidos)
plt.show()

Regplot dos Atributos Usados Para Segmentação¶
É um gráfico de dispersão com uma linha de regressão, para visualizar as relações lineares entre as variáveis. Vamos utilizar para enxergar a relação entre os pedidos.
# Relação Entre os Atributos
# Tamanho da figura
plt.figure(figsize = (15 , 7))
# Inicializa o contador
n = 0
items_list = ['pizza', 'salada', 'sobremesa', 'bebida']
# Loop pelos atributos
for x in items_list:
for y in items_list:
n += 1
plt.subplot(4 , 4 , n)
plt.subplots_adjust(hspace = 0.5 , wspace = 0.5)
sns.regplot(x = x , y = y , data = df_item_pedidos)
plt.ylabel(y)
plt.show()

Uma breve explicação. Quanto mais próximo de 45° a inclinação da reta, maior é a correlação, podemos ler os gráficos como sendo o eixo x a vairável independente e o eixo y como a variável dependente, ou seja, as variáveis, se correlacionadas, aumentam ou diminuem em função de x, porém, um ponto importante a ressaltar, correlação não implica em causalidade. Os gráficos na diagonal com a correlação perfeita são os produtos com eles mesmos, por exemplo o primeiro é pizza com pizza.
Vamos analisar, por exemplo a hipótese de quanto mais pizzas pedidas, também aumentam os pedidos de sobremesa.
Podemos verificar na linha 1 e coluna 3, que o gráfico claramente mostra essa correlação. Com isso podemos supor que o pessoal que gostam de pizza, também gostam de uma sobremesa e por isso sempre pedem o acompanhamento. Mas e bebida também correlaciona com pizza?
Sim! O pessoal que pede pizza também pedem bebida, com isso podemos supor que na maioria dos pedidos de pizza, sempre tem bebida e sobremesa para acompanhamento.
Agora vamos observar os pedidos de salada, tem uma correlação negativa, ou seja quanto mais pizzas pedidas, menores são os pedidos de salada.
Uma outra forma de visualizar a correlação é através de um heatmap, onde podemos ver quantitativamente a força da correlação, utilizando a correção de pearson que varia entre -1 e 1.
# Tamanho da figura
plt.figure(figsize=(10,6))
# plotando gráfico
sns.heatmap(df_item_pedidos[items_list].corr(), vmin=-1, vmax=1, annot=True)
# definindo título
plt.title('Correlação entre os pedidos');

Podemos analisar, aproximadamente, os valores (para mais ou para menos) e podemos comprovar o que antes já havíamos visto graficamente:
- 1.00 à 0.90: correlação muito forte positiva;
- 0.90 à 0.70: correlação forte positiva;
- 0.70 à 0.50: correlação moderada positiva;
- 0.50 à 0.30: correlação fraca positiva;
- 0.30 à 0.00: correlação desprezível;
Definindo as Variáveis Para Segmentação¶
Agora vamos iniciar nosso processo de preparação para a segmentação, inicialmente vamos remover id_transacao, horario_pedido, localidade e mes para nossas primeiras atividades de clusterização.
Vamos utilizar o dataset que fizemos colocando o índice e criar um novo dataframe com o nome df.
# Filtrando o dataframe por colunas
df_item_pedidos_idx[['index', 'bebida', 'pizza', 'sobremesa', 'salada']]
# Vamos gerar um novo dataframe com o slice anterior
df = df_item_pedidos_idx[['index', 'bebida', 'pizza', 'sobremesa', 'salada']]
# Dataset
df.head()
Perfeito. Podemos avançar.
Análise de Cluster¶
Clusterização é um processo de aprendizagem não supervisionada, quando entregamos a um algoritmo de Machine Learning somente os dados de entrada e durante o treinamento, o algoritmo cria um modelo capaz de gerar saídas, nesse caso grupos, ou clusters.
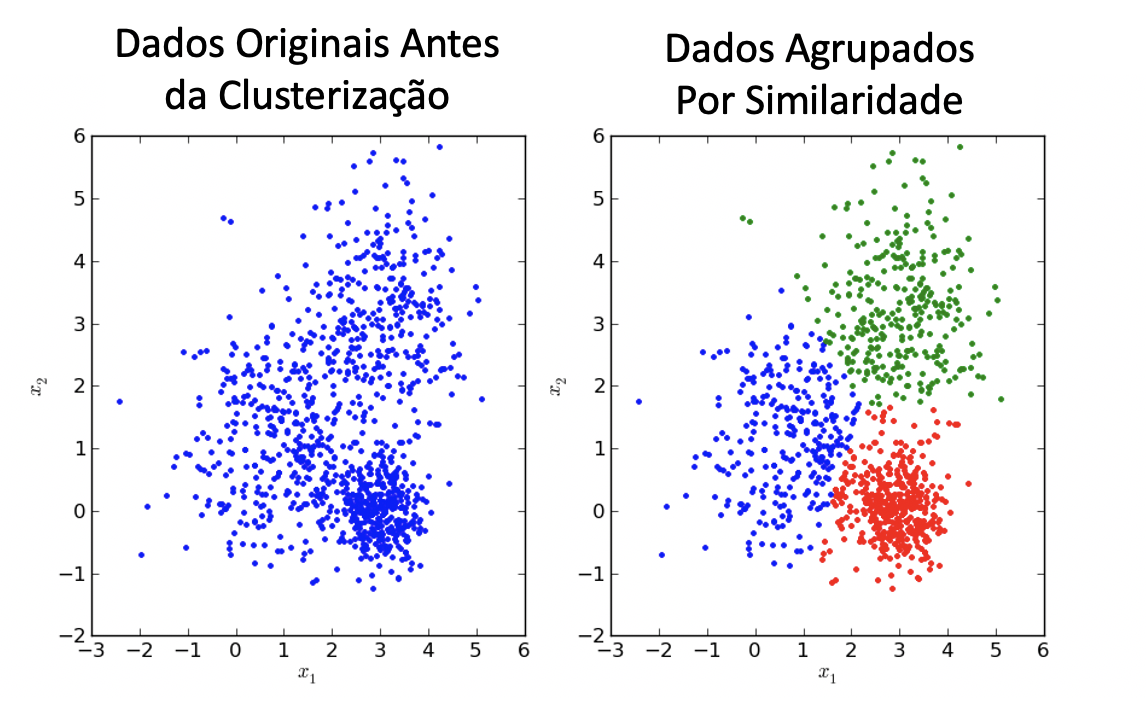
Algoritmo de Clusterização - K-means¶
O K-Means Clustering é um algoritmo de aprendizado de máquina não supervisionado. Em contraste com os algoritmos tradicionais de aprendizado de máquina supervisionado, o K-Means tenta classificar dados sem antes ter sido treinado com dados rotulados. Depois que o algoritmo é executado e os grupos são definidos, qualquer novo dado pode ser facilmente atribuído ao grupo mais relevante.
O K-Means tem a vantagem de ser muito rápido, pois estamos realmente calculando as distâncias entre pontos e centros de grupos; são poucos cálculos! Portanto, possui uma complexidade linear O(n).
Por outro lado, o K-Means tem algumas desvantagens. Primeiro, você deve selecionar quantos grupos / clusters. Isso nem sempre é trivial e, idealmente, com um algoritmo de agrupamento, queremos que ele os descubra, porque o objetivo é obter algumas informações dos dados.
O K-means também começa com uma escolha aleatória de centros de cluster e, portanto, pode produzir resultados de cluster diferentes em execuções diferentes do algoritmo. Assim, os resultados podem não ser repetíveis e não têm consistência. Outros métodos de cluster são mais consistentes.
Métricas de Clusterização - Definição e Interpretação¶
Podemos mencionar 6 métricas de avaliação para clusters, no qual falarei brevemente sobre elas:
- Número de observações: o número de observações em cada cluster na partição final.
A variabilidade de um cluster pode ser afetada por ter um número maior ou menor de observações, é importante examinar os clusters com um número significativamente menor de observações, porque podem conter discrepâncias ou observações incomuns com características únicas.
- Soma de quadrados dentro do cluster: a soma dos desvios ao quadrado de cada observação e do centróide do cluster.
É uma medida da variabilidade das observações dentro de cada cluster. Em geral, um cluster que possui uma pequena soma de quadrados é mais compacto do que um cluster que possui uma grande soma de quadrados, assim como clusters com valores mais altos exibem maior variabilidade das observações dentro do cluster.
- Distância média do centróide: a média das distâncias das observações ao centróide de cada cluster.
Em geral, um cluster que possui uma distância média menor é mais compacto do que um cluster que tem uma distância média maior, assim como clusters com valores mais altos exibem maior variabilidade das observações dentro do cluster.
- Distância máxima do centróide: o máximo das distâncias das observações ao centróide de cada cluster.
Um valor máximo mais alto, especialmente em relação à distancia média, indica uma observação no cluster que fica mais distante do centróide do cluster.
- Centróide do cluster: o meio de um cluster.
Um centróide é um vetor que contém um número para cada variável, e que cada número é a média de uma variável para as observações nesse cluster. O centróide pode ser considerado a média multidimensional do cluster.
- Distâncias entre centróides de cluster: As distâncias entre os centróides do cluster medem a distância entre os centróides dos clusters na partição final.
Você pode comparar as distâncias para ver quão diferentes os clustes são. Uma distância maior geralmente indica uma diferença maior entre os clusters.
Segmentação 1¶
Vamos realizar nossa primeira segmentação usando 2 variáveis, usando pizza e Sobremesa.
# Usaremos duas variáveis
X1 = df[['pizza' , 'sobremesa']].iloc[: , :].values
# Lista do WCSS
wcss_X1 = []
Muitas vezes, os dados com os quais você trabalha têm várias dimensões, dificultando a visualização. Como consequência, o número ideal de clusters não é muito óbvio. Felizmente, temos uma maneira de determinar isso matematicamente.
Representamos graficamente a relação entre o número de clusters e a soma dos quadrados dentro do cluster (Within Cluster Sum of Squares - WCSS) e, em seguida, selecionamos o número de clusters nos quais a mudança no WCSS começa a se estabilizar (Método Elbow).
Segmentação 1 - Encontrando o Valor Ideal de Clusters¶
Vamos testar diferentes valores de K (valores de cluster) entre 2 e 10.
Para a inicialização dos clusters, usamos o algoritmo k-means++ que oferece convergência mais rápida para o resultado final.
# definindo o número de clusters
num_cluster = 10
# Loop para testar os valores de K
for n in range(2, num_cluster+1):
modelo = (KMeans(n_clusters = n,
init = 'k-means++',
n_init = 10,
max_iter = 300,
tol = 0.0001,
random_state = 111,
algorithm = 'elkan'))
modelo.fit(X1)
wcss_X1.append(modelo.inertia_)
# Plot
plt.figure(1 , figsize = (15 ,6))
plt.plot(np.arange(2 , num_cluster+1) , wcss_X1 , 'o')
plt.plot(np.arange(2 , num_cluster+1) , wcss_X1 , '-' , alpha = 0.5)
plt.xlabel('Número de Clusters') , plt.ylabel('WCSS')
plt.show()

Escolhemos o valor ideal de clusters e criamos o modelo final para a Segmentação 1. Observe no gráfico acima que não há certo ou errado. Poderíamos trabalhar com qualquer valor entre 2 e 10 (não faz sentido criar apenas 1 cluster).
O gráfico acima é chamado de Curva de Elbow e normalmente usamos o valor com o menor WCSS. Mas isso deve ser alinhado com as necessidade de negócio. Para esse exemplo, não faria sentido usar 10 clusters. Vamos começar com 2 clusters e avaliar e interpretar os resultados.
Após a definição da quantidade de cluster à ser utilizado, lembrando que menor o WCSS mais homogêneo será o grupo, treina-se o modelo. Neste caso, vamos treinar o modelo com dois clusters.
Segmentação 1 - Construindo e Treinando o Modelo¶
# Criação do modelo
modelo_seg1 = KMeans(n_clusters = 2,
init = 'k-means++',
n_init = 10,
max_iter = 300,
tol = 0.0001,
random_state = 111,
algorithm = 'elkan')
# Treinamento do modelo
modelo_seg1.fit(X1)
# Extração dos labels
labels1 = modelo_seg1.labels_
labels1
# Extração dos centróides
centroids1 = modelo_seg1.cluster_centers_
centroids1
Esses valores são o vetor dos centroides dos grupos, vamos visualizar graficamente.
Segmentação 1 - Visualização e Interpretação dos Segmentos¶
# Plot
# Parâmetros do Meshgrid
h = 0.02
x_min, x_max = X1[:, 0].min() - 1, X1[:, 0].max() + 1
y_min, y_max = X1[:, 1].min() - 1, X1[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = modelo_seg1.predict(np.c_[xx.ravel(), yy.ravel()])
plt.figure(1 , figsize = (15, 7) )
plt.clf()
Z = Z.reshape(xx.shape)
# Plot da imagem
plt.imshow(Z,
interpolation = 'nearest',
extent = (xx.min(), xx.max(), yy.min(), yy.max()),
cmap = plt.cm.Set2,
aspect = 'auto',
origin = 'lower')
# Plot dos pontos de dados
plt.scatter( x = 'pizza', y = 'sobremesa', data = df, c = labels1, s = 200 )
plt.scatter(x = centroids1[: , 0], y = centroids1[: , 1], s = 300, c = 'red', alpha = 0.5)
plt.xlabel('Pizza')
plt.ylabel('Sobremesa')
plt.show()

Interpretação:
- O ponto vermelho é o centróide de cada cluster (segmento).
- No cluster 1 (área em verde) temos os clientes que pediram 0, 1 ou 2 Pizzas. Em todos os casos houve pedido de Sobremesa.
- No cluster 2 (área em cinza) estão clientes que pediram 2, 3, 4 ou 5 Pizzas. Perceba que à medida que o pedido tem maior número de Pizzas, também aumenta o número de Sobremesas.
Análise:
Cluster 1 - Clientes que pedem menos Pizzas. Todos pedem sobremesa.
Cluster 2 - Clientes que pedem mais Pizzas. Todos pedem sobremesa em volume maior.
Como estratégia de Marketing, poderíamos oferecer ao cliente uma sobremesa grátis no caso de comprar mais uma Pizza de maior valor. Com base na Segmentação provavelmente essa estratégia teria sucesso.
Segmentação 2¶
Vamos criar agora um modelo com as variáveis Pizza e Salada, dessa vez com 3 clusters.
# Usaremos duas variáveis
X1 = df[['pizza' , 'salada']].iloc[: , :].values
# Lista de valores de Inertia (Inertia e WCSS são a mesma coisa)
inertia = []
# Loop para testar os valores de K
for n in range(2 , 11):
modelo = (KMeans(n_clusters = n,
init = 'k-means++',
n_init = 10,
max_iter = 300,
tol = 0.0001,
random_state = 111,
algorithm = 'elkan'))
modelo.fit(X1)
inertia.append(modelo.inertia_)
# Plot
plt.figure(1 , figsize = (15 ,6))
plt.plot(np.arange(2 , 11) , inertia , 'o')
plt.plot(np.arange(2 , 11) , inertia , '-' , alpha = 0.5)
plt.xlabel('Número de Clusters') , plt.ylabel('Inertia')
plt.show()

Vamos criar o modelo com 3 clusters.
# Criação do modelo com 3 clusters
modelo_seg2 = (KMeans(n_clusters = 3,
init = 'k-means++',
n_init = 10 ,
max_iter = 300,
tol = 0.0001,
random_state = 111 ,
algorithm = 'elkan') )
# Treinamento do modelo
modelo_seg2.fit(X1)
# Labels
labels2 = modelo_seg2.labels_
# Centróides
centroids2 = modelo_seg2.cluster_centers_
# Plot
# Parâmetros do Meshgrid
h = 0.02
x_min, x_max = X1[:, 0].min() - 1, X1[:, 0].max() + 1
y_min, y_max = X1[:, 1].min() - 1, X1[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = modelo_seg2.predict(np.c_[xx.ravel(), yy.ravel()])
plt.figure(1 , figsize = (15, 7) )
plt.clf()
Z = Z.reshape(xx.shape)
# Plot da imagem
plt.imshow(Z,
interpolation = 'nearest',
extent = (xx.min(), xx.max(), yy.min(), yy.max()),
cmap = plt.cm.Dark2,
aspect = 'auto',
origin = 'lower')
# Plot dos pontos de dados
plt.scatter( x = 'pizza', y = 'salada', data = df, c = labels2, s = 200 )
plt.scatter(x = centroids2[: , 0], y = centroids2[: , 1], s = 300, c = 'red', alpha = 0.5)
plt.xlabel('Pizza')
plt.ylabel('Salada')
plt.show()

Interpretação:
- O ponto vermelho é o centróide de cada cluster (segmento).
- No cluster 1 (área em cinza) temos os clientes que pediram menos Pizzas e mais Saladas.
- No cluster 2 (área em verde escuro) temos os clientes que pediram poucas Pizzas e poucas Saladas.
- No cluster 3 (área em verde claro) estão clientes que pediram mais Pizzas e menos Saladas.
Análise:
Os clusters 1 e 3 são de clientes com comportamentos opostos. A equipe de Marketing poderia concentrar os esforços nos clientes do cluster 2, pois são clientes que compram Pizzas e Saladas e, portanto, tendem a consumir mais itens variados evitando manter os estoques cheios de um único item.
Ou então, concentrar os esforços nos clientes que consomem produtos que geram mais lucro. Teríamos que verificar qual item, Pizza ou Salada, é mais rentável.
Segmentação 3¶
Segmentação 3 - Variáveis Pizza, Salada e Sobremesa
# Usaremos três variáveis
X1 = df[['pizza' , 'salada' , 'sobremesa']].iloc[: , :].values
# Lista de valores de Inertia (Inertia e WCSS são a mesma coisa)
inertia = []
# Loop para testar os valores de K
for n in range(2 , 11):
modelo = (KMeans(n_clusters = n,
init = 'k-means++',
n_init = 10,
max_iter = 300,
tol = 0.0001,
random_state = 111,
algorithm = 'elkan'))
modelo.fit(X1)
inertia.append(modelo.inertia_)
# Plot
plt.figure(1 , figsize = (15 ,6))
plt.plot(np.arange(2 , 11) , inertia , 'o')
plt.plot(np.arange(2 , 11) , inertia , '-' , alpha = 0.5)
plt.xlabel('Número de Clusters') , plt.ylabel('Inertia')
plt.show()

Vamos criar o modelo com 2 clusters.
# Criação do modelo com 2 clusters
modelo_seg3 = (KMeans(n_clusters = 2,
init = 'k-means++',
n_init = 10 ,
max_iter = 300,
tol = 0.0001,
random_state = 111 ,
algorithm = 'elkan') )
# Treinamento do modelo
modelo_seg3.fit(X1)
# Labels
labels3 = modelo_seg3.labels_
# Centróides
centroids3 = modelo_seg3.cluster_centers_
# Plot
# Gráfico 3D
grafico = go.Scatter3d(x = df['pizza'],
y = df['salada'],
z = df['sobremesa'],
mode = 'markers',
marker = dict(color = labels3,
size = 4,
line = dict(color = labels3, width = 15),
opacity = 0.7))
# Layout do gráfico
layout = go.Layout(title = 'Clusters',
scene = dict(xaxis = dict(title = 'Pizza'),
yaxis = dict(title = 'Salada'),
zaxis = dict(title = 'Sobremesa')))
# Plot da figura (gráfico + layout)
fig = go.Figure(data = grafico, layout = layout)
py.offline.iplot(fig)
Interpretação:
- Observamos a clara separação entre os dados dois 2 clusters.
- Cada ponto de dado representa uma coordenada de 3 dimensões.
Análise:
Aqui o ideal é avaliar o gráfico de forma interativa aproveitando essa propriedade do Plotly.
Segmentação 4¶
Por fim vamos utilizar todas as variáveis, pizza, bebida, salada e sobremesa.
# Usaremos três variáveis
X1 = df[['pizza' , 'bebida', 'salada' , 'sobremesa']].iloc[: , :].values
# Lista de valores de Inertia (Inertia e WCSS são a mesma coisa)
inertia = []
# Loop para testar os valores de K
for n in range(2 , 11):
modelo = (KMeans(n_clusters = n,
init = 'k-means++',
n_init = 10,
max_iter = 300,
tol = 0.0001,
random_state = 111,
algorithm = 'elkan'))
modelo.fit(X1)
inertia.append(modelo.inertia_)
# Plot
plt.figure(1 , figsize = (15 ,6))
plt.plot(np.arange(2 , 11) , inertia , 'o')
plt.plot(np.arange(2 , 11) , inertia , '-' , alpha = 0.5)
plt.xlabel('Número de Clusters') , plt.ylabel('Inertia')
plt.show()

# Criação do modelo com 5 clusters
modelo_seg4 = (KMeans(n_clusters = 5,
init = 'k-means++',
n_init = 10 ,
max_iter = 300,
tol = 0.0001,
random_state = 111 ,
algorithm = 'elkan') )
# Treinamento do modelo
modelo_seg4.fit(X1)
# Labels
labels4 = modelo_seg4.labels_
# Centróides
centroids4 = modelo_seg4.cluster_centers_
pd.DataFrame(data = modelo_seg4.cluster_centers_, columns = [df[['pizza' , 'bebida', 'salada' , 'sobremesa']]])
modelo_seg4.cluster_centers_.shape
PCA¶
Com 5 clusters fica difícil de visualizar, então vamos utilizar outro algoritmo que é o PCA, com ele podemos reduzir a dimensionalidade de 5 para 2, por exemplo, assim conseguiremos visualizar graficamente.
Vamos agora construir o nosso gráfico.
df_cluster = pd.concat([df,pd.DataFrame({'cluster':labels4})], axis = 1)
features = ['pizza' , 'bebida', 'salada' , 'sobremesa']
X2 = df_cluster[features]
pca = PCA(n_components=2)
components = pca.fit_transform(X2)
loadings = pca.components_.T * np.sqrt(pca.explained_variance_)
fig = px.scatter(components, x=0, y=1, color=df_cluster['cluster'])
for i, feature in enumerate(features):
fig.add_shape(
type='line',
x0=0, y0=0,
x1=loadings[i, 0],
y1=loadings[i, 1]
)
fig.add_annotation(
x=loadings[i, 0],
y=loadings[i, 1],
ax=0, ay=0,
xanchor="center",
yanchor="bottom",
text=feature,
)
fig.show()
Quando trabalhamos com muitas colunas, o ideal é checar, assim como o número de clusters, a quantidade de dimensões ideal.
Não é muito o nosso caso, pois temos somente 4 colunas, mas para efeito de demonstração e check vamos verificar a quantidade de dimensões ideal para nosso conjunto.
pca = PCA()
pca.fit(X2)
exp_var_cumul = np.cumsum(pca.explained_variance_ratio_)
px.area(
x=range(1, exp_var_cumul.shape[0] + 1),
y=exp_var_cumul,
labels={"x": "# Components", "y": "Explained Variance"}
)
O ideal é que o modelo consiga explicar o máximo de variancia entre as variáveis, podemos ver que q com 2 componentes a variância explicada é de aproximadamente 92% e com 3 componentes a variância explicada passa a ser de 99%.
Vamos rodar novamente, com 3 componentes, que julgamos ser o nosso número ideal e com 3 dimensões, conseguimos gerar um gráfico em 3D.
pca = PCA(n_components=3)
components = pca.fit_transform(X2)
total_var = pca.explained_variance_ratio_.sum() * 100
fig = px.scatter_3d(
components, x=0, y=1, z=2, color=df_cluster['cluster'],
title=f'Total Explained Variance: {total_var:.2f}%',
labels={'0': 'PC 1', '1': 'PC 2', '2': 'PC 3'}
)
fig.show()
Relatório final (Considerando a Segmentação 4)
Para finalizar, vamos converter as labels do modelo 4 em dataframe e fazer o merge do dataframe com as labels (clusters), encontrados pelo modelo.
# Visualiza
df_cluster
Então, vamos pegar as informações do arquivo original como id, data e horario do pedido e acrescentar com as informações de clusters e exportar para excel.
# acrescentando as labels
df_final = df_item_pedidos_idx.merge(df_cluster['cluster'], left_index = True, right_index = True)
# criando o arquivo em excel
writer = pd.ExcelWriter('df_cluster.xlsx', engine='xlsxwriter')
# convertendo o dataframe em um objeto do excel
df_final.to_excel(writer, sheet_name='Clusters', index=False)
# salvando o objeto convertendo no arquivo em excel
writer.save()
Conclusão¶
Criamos um modelos de marketing analytics utilizando algoritmo não-supervisionado com KMeans e conforme fomos incrementando a quantidade de features, fica difícil para o ser humano visualizar mais de 3 dimensões então contamos com o auxilio de outro framework que reduz essa dimensionalidade, que o PCA assim conseguimos com mais facilidade analisar um conjunto com muitas features, depois salvamos o resultado em uma planilha em excel e podemos até criar um dashboard em Power BI por exemplo e entregar para a equipe de Marketing.